
국내 온라인 도서 플랫폼에는 이렇게 있는데 처음 생각한 것은 알라딘, 교보문고 였다.
하지만 이 자료를 보고 yes24를 메인으로 해야겠다고 결정.
( 이렇게까지 플랫폼간의 갭이 있는지 이번에 알았다..비유하자면 UI가 뭔가 yes24는 옥션,지마켓 느낌이고 알라딘은 쿠팡,마켓컬리 같은 느낌이라... )
그리고 yes24를 고른 또다른 이유는 다른 플랫폼에는 privacy를 위해서인지 rating data에 blur처리가 되있는 반면 , yes24는 다 노출이 되어있어서 더 용이하다고 판단하였다.

하지만 결정 할 것이 많이 있었다. 모든 책을 대상으로 진행할지 ,실제로 서비스를 할 것인가, 공부와 연습을 위한 것인가 나는 어떤 직군으로 취업을 희망하는가를..
처음 계획은 모든 책을 하려고 했지만 선택과 집중을 하였다. 소설을 대상으로 구현하기로. 모델을 학습하고 성능을 위해서는 물론 데이터량이 매우 중요하지만 그 곳에 빠지지 않기로 하였다.
소설만 하더라도 현재 yes24에만 있는 책이 10만권 이상이 있었다. 충분하다고 판단하였다. 그리고 밑에 그림을 보면 yes24를 보면 카테고리가 잘 구분되어있다. 상위 카테고리부터 하위 카테고리까지.
카테고리별로 살펴보니 카테고리별로 중복된 책들이 많이 있었다. 파란테두리(장르소설,테마소설,고전문학)이 9만여권 , 초록색 테두리(한국소설,영미소설, ... , 세계각국소설)가 7만여권 이었다.
파란테두리가 더 큰 집합으로 판단. 파란테두리 책들을 BeautifulSoup을 이용해서 크롤링 하였다. csv로 확인하다 책들이 다 크롤링 되었는지 확인하고 싶어졌고, 최근 이슈화가 됬거나 인기가 있던 책들 제목을 검색하다가 '82년생 공지영' 을 검색했는데
없었다....
책마다 여러카테고리에 속한 책도 있고 아닌 책들도 있는 것이었다. 상위집합, 하위집합 개념이 아니었다.
그래서 2차로 초록네모 책들도 크롤링해서 중복된 책정보는 drop_duplicated 하기로 하였다.
한 페이지 당 20개씩 노출되 있는 각 책의 link(url)을 페이지별로 먼저 크롤링, 그 후 각 책당 원하는 feature들을 크롤링 하였다. 크롤링 하면서 있는 None값들은 각 feature별(제목일 경우 : 'no_title', 번역가일 경우 :'no_translator' )로 except: 를 이용해서 정리해주었다.

2.리뷰데이터를 크롤링.
yes24에는 이렇게 리뷰가 있고 , 한줄평이 있다.

리뷰는 유저가 정성들여 작성한다. feature가 모자르거나 성능이 부족하면 리뷰에서 keyword를 뽑아내거나 유저의 만족도를 나타내는 단어(최고에요, 추천합니다,인생작,띵작 등등..)가 나타나는 횟수에 따라 user의 explicit rating과 조합해서 더 세분화 할 계획이다.

다음으로 한줄평 데이터이다.
평가를 한 사람수 , 총평균 , 유저의 rating, 유저의 한줄평 , 유저의 아이디, 평가날짜 를 크롤링하였다.
한줄평은 말 그래도 가볍게 피드백을 남긴다

하지만 기존방법처럼 url을 지정해서 css태그를 이용해서는 리뷰와 한줄평 데이터가 크롤링 되지않았다. 다른 url로 접속해서 가져와야만 했다. 웹이 java기반으로 꾸며져있어 이렇게 간혹 숨겨져(?)있는 것들이 있다고 한다.
F12로 html 을 확인한다. XHR 탭에서 preview로 원하는 데이터인지 체크해서 headers에 있는 Request URL 에서 ?앞까지가 원하는 url 이다. (쿼리스트링를 뺀 스키마부터 호스트,path 까지)
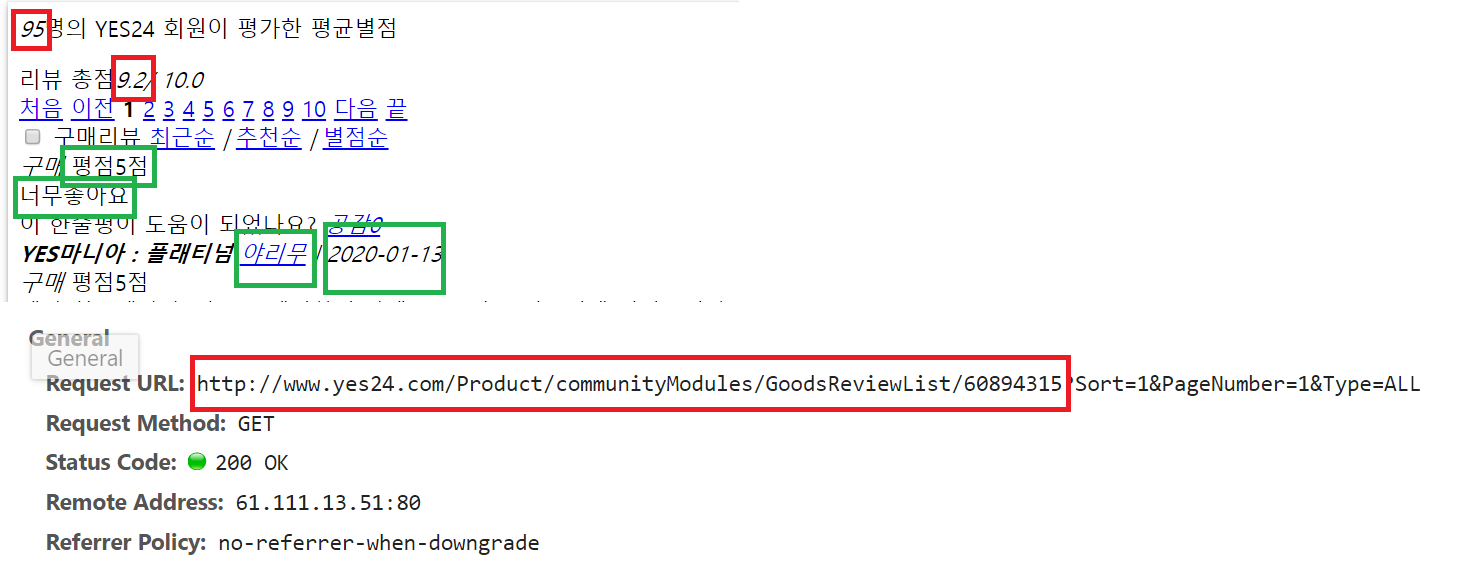
이렇게 크롤링해서 각 책마다 있는 책url로 merge하였다.
하지만 또 문제가 있었다. content-based filtering 하기에는 category 와 keyword 칼럼에 none값이 너무 많았다.
그래서 교보문고에서 keyword 와 category를 추가로 크롤링 해서 합쳐주었다.
'빅데이터 > 추천시스템' 카테고리의 다른 글
| Item-based 를 들어가기전에 (np.corrcoef, .corr 연습)- 추천시스템(5) (0) | 2020.03.18 |
|---|---|
| Content-based-filtering(컨텐츠기반 필터링) - 추천시스템(4) (0) | 2020.03.11 |
| 데이터 전처리 - 추천시스템(3) (0) | 2020.03.06 |
| 추천시스템에 대한 이해 - 추천시스템(2) (0) | 2020.03.04 |
| 추천시스템 구현 방향 (0) | 2020.03.04 |


